08 - NVIDIA Jetson Nano
Systemy Wbudowane i Przetwarzanie Brzegowe
Politechnika Poznańska, Instytut Robotyki i Inteligencji Maszynowej
![]()
Ćwiczenie laboratoryjne 08: NVIDIA Jetson Nano
Powrót do spisu treści ćwiczeń laboratoryjnych
Wstęp
NVIDIA Jetson Nano jest to mały wydajny komputer jednopłytkowy (SBC - Single Board Computer) przeznaczony do zastosowań związanych z uczeniem maszynowym oraz przetwarzaniem obrazów. Urządzenie to jest wyposażone w procesor graficzny (GPU) NVIDIA Maxwell z 128 rdzeniami CUDA, procesor ARM Cortex-A57 4 rdzeniowy, oraz 4GB pamięci RAM. Urządzenie to jest kompatybilne z wysokowydajną biblioteką TensorRT oraz platformą do obliczeń równoległych CUDA.
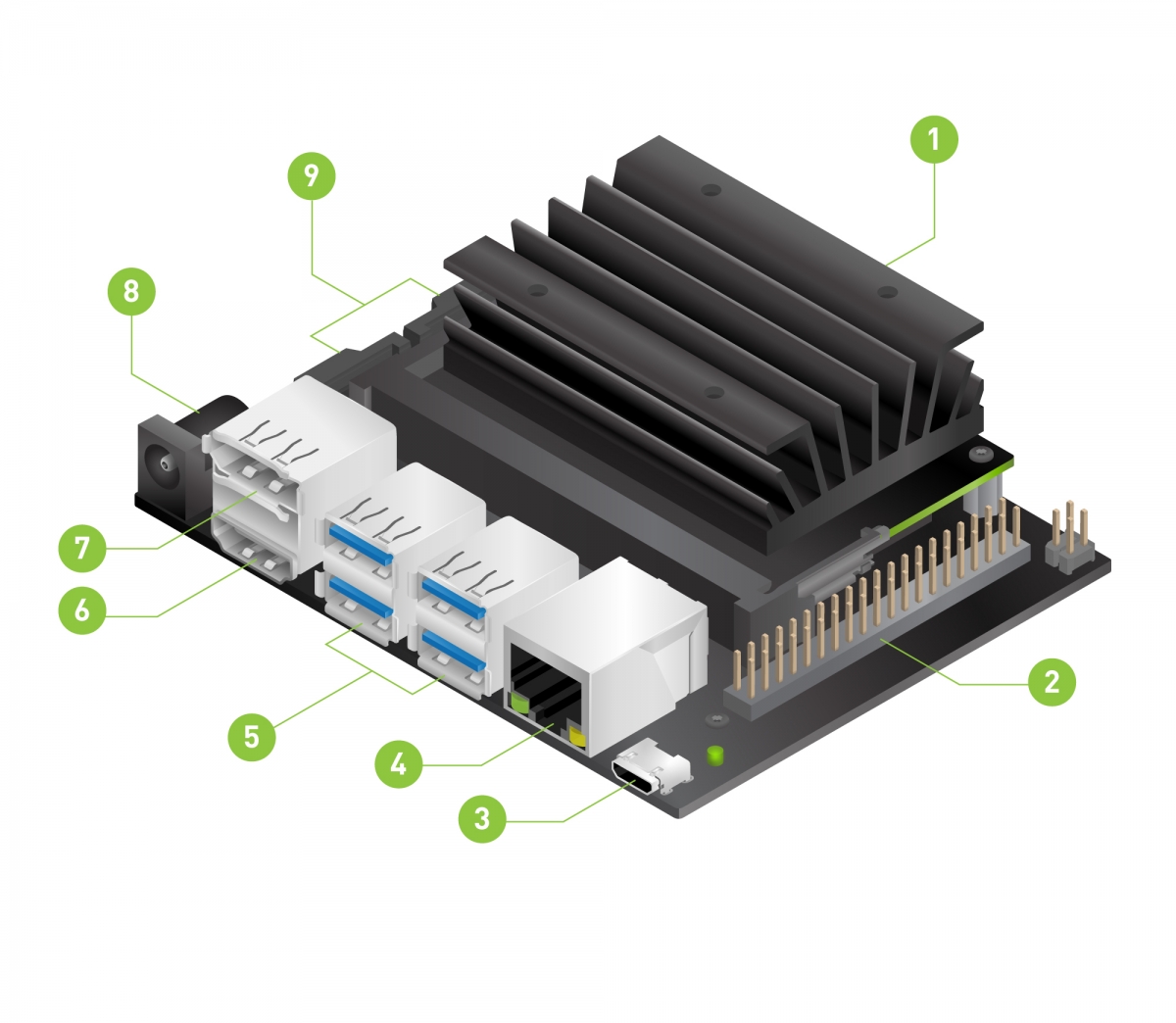 Źródło grafiki:
Getting
Started with Jetson Nano Developer Kit
Źródło grafiki:
Getting
Started with Jetson Nano Developer Kit
Na powyższym schemacie wymienione są następujące komponenty: 1. slot na kartę microSD, na której znajduje się system operacyjny 2. rozszerzenie do obsługi 40 pinów GPIO 3. micro-USB do obsługi komunikacji z hostem lub zasilania 4. port do obsługi ethernetu 5. porty USB 3.0 6. port HDMI 7. DisplayPort 8. DC Barrel Jack do zasilania z zewnętrznego zasilacza 5V 4A 9. MIPI CSI-2 port do obsługi kamery
Przygotowanie karty SD z obrazem systemu operacyjnego
Wszystkie niezbędne informacje oraz kroki, które należy wykonać aby przygotować urządzenia typu NVIDIA Jetson Nano można znaleźć w instrukcji Getting Started with Jetson Nano Developer Kit.
UWAGA: karty SD z systemem operacyjnym NVIDIA JetPack zostały już przygotowane przez prowadzącego i nie należy ich nadpisywać. Powyższa instrukcja odnosi się jedynie do użytkowania poza zajęciami.
Uruchomienie systemu
Komputery PC oraz NVIDIA Jetson Nano znajdują się w jednej sieci
lokalnej. W celu uzyskania dostępu do urządzenia należy wykonać
następujące kroki: 1. Zasilić urządzenie i podłączyć je do sieci
lokalnej za pomocą kabla ethernetowego lub poprzez adapter do sieci
WIFI. 2. Korzystając z komendy ssh połączyć się z
urządzeniem. Hasło i login to swpb. 3. W celu przesyłania
obrazu poprzez połączenie SSH należy skorzystać z X11
forwarding. W takim przypadku, przy łączeniu z urządzeniem należy
dodać opcję -X. Przykładowo:
ssh -X swpb@192.168.55.1
CUDA
NVIDIA CUDA jest to uniwersalna architektura graficznych procesorów wielordzeniowych (GPU) umożliwiająca wykorzystanie ich mocy obliczeniowej do rozwiązywania ogólnych problemów numerycznych w wydajniejszy sposób niż przy użyciu tradycyjnych, sekwencyjnych procesorach ogólnego zastosowania (CPU). Zestaw narzędzi CUDA zawiera biblioteki z akceleracją GPU, kompilator, narzędzia deweloperskie oraz środowisko uruchomieniowe. Powyższe komponenty są wspierane przez powszechnie używane języki programowania takie jak C++ lub Python.
TensorRT
TensorRT to oprogramowanie opracowane przez NVIDIA, które umożliwia optymalizację i przyspieszenie modeli sieci neuronowych na platformach GPU. Dzięki TensorRT można skutecznie wykorzystać moc obliczeniową GPU, osiągając wysoką wydajność i niskie opóźnienia. Oprogramowanie to automatycznie optymalizuje modele, redukując liczbę operacji oraz minimalizując zużycie pamięci, co przekłada się na szybsze i bardziej efektywne przetwarzanie danych.
 Źródło grafiki:
TensorRT
Źródło grafiki:
TensorRT
Zadania do samodzielnej realizacji
Zadanie 1. Korzystając z interaktywnej instrukcji
przetestuj i wyeksportuj model detekcji obiektów YOLOv8 do formatu ONNX.
Następnie przetestuj jego działanie w środowisku chmurowym z
wykorzystaniem biblioteki ONNX Runtime oraz akceleratorów CPU,
CUDA, oraz TensorRT. Sprawdzony model pobierz i
prześlij na urządzenie NVIDA Jetson Nano korzystając z polecenia
scp.
Zadanie 2. Uzupełnij poniższy skrypt. Uruchom skrypt na urządzeniu NVIDIA Jetson Nano i sprawdź czas wykonywania modelu z wykorzystaniem biblioteki ONNX Runtime oraz akceleratorów CPU, CUDA, oraz TensorRT.
detector_inference.py
import time
import cv2
import numpy as np
import onnxruntime as ort
MODEL_PATH = 'yolov8n.onnx'
CONF_THRESHOLD = 0.5
IOU_THRESHOLD = 0.1
CLASSES = [
'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat',
'traffic light', 'fire hydrant', 'street sign', 'stop sign', 'parking meter', 'bench', 'bird', 'cat',
'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'hat', 'backpack', 'umbrella',
'shoe', 'eye glasses', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'plate',
'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli',
'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'mirror',
'dining table', 'window', 'desk', 'toilet', 'door', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'blender', 'book', 'clock', 'vase',
'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
def nms(boxes, scores):
# Sort by score
sorted_indices = np.argsort(scores)[::-1]
keep_boxes = []
while sorted_indices.size > 0:
# Pick the last box
box_id = sorted_indices[0]
keep_boxes.append(box_id)
# Compute IoU of the picked box with the rest
ious = compute_iou(boxes[box_id, :], boxes[sorted_indices[1:], :])
# Remove boxes with IoU over the threshold
keep_indices = np.where(ious < IOU_THRESHOLD)[0]
# print(keep_indices.shape, sorted_indices.shape)
sorted_indices = sorted_indices[keep_indices + 1]
return keep_boxes
def compute_iou(box, boxes):
# Compute xmin, ymin, xmax, ymax for both boxes
xmin = np.maximum(box[0], boxes[:, 0])
ymin = np.maximum(box[1], boxes[:, 1])
xmax = np.minimum(box[2], boxes[:, 2])
ymax = np.minimum(box[3], boxes[:, 3])
# Compute intersection area
intersection_area = np.maximum(0, xmax - xmin) * np.maximum(0, ymax - ymin)
# Compute union area
box_area = (box[2] - box[0]) * (box[3] - box[1])
boxes_area = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
union_area = box_area + boxes_area - intersection_area
# Compute IoU
iou = intersection_area / union_area
return iou
def xywh2xyxy(xywh):
xyxy = np.copy(xywh)
xyxy[..., 0] = xywh[..., 0] - xywh[..., 2] / 2 # top left x
xyxy[..., 1] = xywh[..., 1] - xywh[..., 3] / 2 # top left y
xyxy[..., 2] = xywh[..., 0] + xywh[..., 2] / 2 # bottom right x
xyxy[..., 3] = xywh[..., 1] + xywh[..., 3] / 2 # bottom right y
return xyxy
def draw_predictions(image, boxes, scores, class_ids, indices, fps):
cv2.putText(image, f'FPS: {fps}', (10, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.60, [225, 255, 255], thickness=2)
for (bbox, score, label) in zip(xywh2xyxy(boxes[indices]), scores[indices], class_ids[indices]):
bbox = bbox.round().astype(np.int32).tolist()
cls_id = int(label)
cls = CLASSES[cls_id]
color = (0,255,0)
cv2.rectangle(image, tuple(bbox[:2]), tuple(bbox[2:]), color, 2)
cv2.putText(image,
f'{cls}: {int(score*100)}%', (bbox[0], bbox[1] - 2),
cv2.FONT_HERSHEY_SIMPLEX,
0.60, [225, 255, 255],
thickness=1)
def preprocess(image, input_shape):
"""
Funkcja przetwarzania wstępnego realizuje następujące kroki:
1. zmienia rozmiar obrazu wejściowego, korzystając ze zmiennej _input_shape_,
2. jeśli wykorzystywana jest biblioteka OpenCV to konwertuje z formatu BGR do RGB
3. skaluje wartości w obrazie do zakresu <0; 1>,
4. zmienia układ wymiarów z _HWC_ na _CHW_ (z formatu _channel last_ na _channel first_)
5. dodaje dodatkowy wymiar do tensora, tak aby był w formacie _NHWC_ (_N_=1)
6. ustawia format danych na _float32_
"""
##### Student code #####
input_tensor = None
########################
return input_tensor
def main():
##### Student code #####
providers = ...
ort_session = ...
########################
print(f'Model loaded with {providers[0]}')
model_inputs = ort_session.get_inputs()
input_names = [model_inputs[i].name for i in range(len(model_inputs))]
input_shape = model_inputs[0].shape
model_output = ort_session.get_outputs()
output_names = [model_output[i].name for i in range(len(model_output))]
input_height, input_width = input_shape[2:]
print('Model warm-up...')
for _ in range(10):
_ = ort_session.run(output_names, {input_names[0]: np.random.rand(1, 3, input_height, input_width).astype(np.float32)})[0]
print('Model ready!')
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit()
prev_frame_time = new_frame_time = 0
while True:
ret, frame = cap.read()
if not ret:
print("Can't receive frame. Exiting...")
break
new_frame_time = time.time()
image_height, image_width = frame.shape[:2]
input_tensor = preprocess(frame, input_shape=(input_width, input_height))
outputs = ort_session.run(output_names, {input_names[0]: input_tensor})[0]
predictions = np.squeeze(outputs).T
# Filter out object confidence scores below threshold
scores = np.max(predictions[:, 4:], axis=1)
predictions = predictions[scores > CONF_THRESHOLD, :]
scores = scores[scores > CONF_THRESHOLD]
# Get the class with the highest confidence
class_ids = np.argmax(predictions[:, 4:], axis=1)
# Get bounding boxes for each object
boxes = predictions[:, :4]
# Rescale box
input_shape = np.array([input_width, input_height, input_width, input_height])
boxes = np.divide(boxes, input_shape, dtype=np.float32)
boxes *= np.array([image_width, image_height, image_width, image_height])
boxes = boxes.astype(np.int32)
# Apply non-maxima suppression to suppress weak, overlapping bounding boxes
indices = nms(boxes, scores)
# Calculate frames per second rate
fps = round(1 / (new_frame_time - prev_frame_time), 1)
draw_predictions(frame, boxes, scores, class_ids, indices, fps)
cv2.imshow('Predictions', frame)
if cv2.waitKey(1) == ord('q'):
break
prev_frame_time = new_frame_time
if __name__ == '__main__':
main()
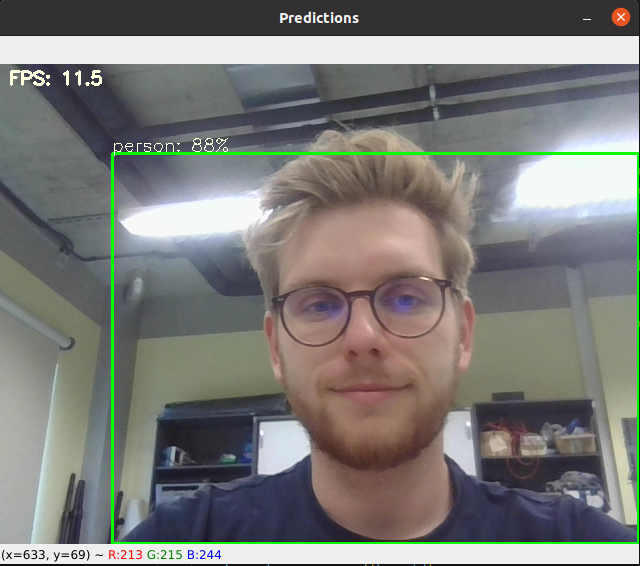
Zadanie 3. Korzystając ze skryptu z laboratorium 07 - Inferencja sieci neuronowej z wykorzystaniem Raspberry Pi i ONNX Runtime oraz modelu ONNX (w formacie FLOAT32) z instukcji 06 - Metody optymalizacji sieci neuronowych przetestuj działanie i sprawdź czas wykonywania modelu segmentacyjnego na platformie Jetson Nano. Porównaj dostępne w bibliotece ONNX Runtime akceleratory - CPU, CUDA, oraz TensorRT.