10 - Foundation models and knowledge distillation
Advanced Image Processing
Poznan University of Technology, Institute of Robotics and Machine Intelligence
![]()
Laboratory 10: Foundation Models & Knowledge Distillation
Introduction
In the modern era of Computer Vision, the paradigm has shifted from training models from scratch (like ResNet) to adapting massive Foundation Models (like CLIP or ViT) that have been pre-trained on millions of images. However, deploying these massive models on edge devices is often impossible due to hardware constraints.
This laboratory is divided into two parts to address this full lifecycle:
- Foundation Models: You will learn how to extract powerful visual features or leverage the power of large pre-trained models using Zero-Shot inference.
- Knowledge Distillation: You will learn how to compress a massive “Teacher” model into a tiny “Student” model suitable for production, retaining as much accuracy as possible.
Goals
The objectives of this laboratory are to:
- Perform Linear Probing: Train a classifier on top of frozen foundation model features.
- Implement LoRA (Low-Rank Adaptation) to fine-tune a Vision Transformer.
- Implement a Knowledge Distillation loop to transfer knowledge from a Teacher to a Student.
- Evaluate the trade-offs between model size, inference latency, and accuracy.
Resources
- DINOv2: Learning Robust Visual Features without Supervision
- LoRA: Low-Rank Adaptation of Large Language Models
- Distilling the Knowledge in a Neural Network
- PyTorch Image Models (timm)
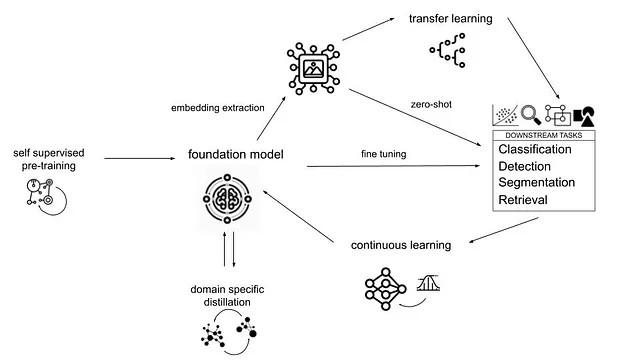
Image source:
Foundation
Models: A New Vision for E-commerce
Prerequisites
Install dependencies
First, let’s set up our Python environment with all necessary dependencies.
PyTorch
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu126Other Deep Learning-related libraries
pip install transformers datasets peft timmMetrics and visualization
pip install matplotlib scikit-learnVision Foundation Models
Feature Extraction with DINOv2
DINOv2 (Self-distillation with no labels) is a Foundation Model from Meta AI. Unlike supervised models (trained on ImageNet labels), DINOv2 learns by “looking” at images and understanding object geometry, texture, and depth without ever being told “this is a cat”. Because it understands visual structure so well, we don’t need to train it. We can simply use it as a Feature Extractor for further processing.

Image source: DINOv2:
Learning Robust Visual Features without Supervision
💥 Task 1 💥
Load facebook/dinov2-base model from
transformers package and use it to extract features from
CIFAR-10 images. Then, train a simple sklearn linear classifier on these
features (Linear Probing). Finally, visualize features using t-SNE.
Your task is to complete the following code gaps:
- Feature Extraction (
extract_embeddingsfunction):- Move the model to the appropriate device (CPU/CUDA) and set it to evaluation mode
- Convert each image to RGB format (CIFAR-10 images should already be RGB)
- Forward the image through the model and extract the CLS token
embeddings from
last_hidden_stateat index 0 - Append the extracted embeddings to the list (expected shape per
image:
[1, 768])
- Linear Classifier Training (
mainfunction):- Train a linear classifier (e.g.,
LogisticRegression) on the extracted training embeddings - Evaluate the classifier on both training and test sets
- Compute accuracy scores for both sets
- Train a linear classifier (e.g.,
The code will automatically generate a t-SNE visualization showing how DINOv2 separates the 10 CIFAR-10 classes in the feature space.
DINOv2_feature_extraction.py
import matplotlib.pyplot as plt
import numpy as np
import torch
from datasets import load_dataset
from sklearn.manifold import TSNE
from transformers import AutoImageProcessor, AutoModel
from tqdm import tqdm
# Configuration
MAX_TRAIN_SAMPLES = 5000
MAX_TEST_SAMPLES = 1000
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
def extract_embeddings(model, processor, images):
"""Extract embeddings from images using DINOv2 model."""
all_embeddings = []
############# TODO: Student code #####################
# Step 1: Move model to DEVICE and set to eval mode
for img in tqdm(images, desc="Extracting embeddings"):
# Step 2: Convert to RGB
# Process single image
inputs = processor(images=img, return_tensors="pt")
inputs = {k: v.to(DEVICE) for k, v in inputs.items()}
# Step 3: Forward model and extract CLS token embeddings (at index 0) from last hidden state
# Expected model output.last_hidden_state shape: (1, sequence_length, hidden_size)
# In DINOv2 base model hidden_size is 768 and sequence_length depends on input image size
# Expected CLS token embeddings shape: torch.Size([1, 768])
with torch.no_grad():
pass
# Step 4: Append embeddings to all_embeddings
######################################################
return np.concatenate(all_embeddings, axis=0)
def visualize_features(features: np.ndarray, labels: np.ndarray, class_names: list[str], n_samples: int = 1000) -> plt.Figure:
"""Visualize features using t-SNE."""
if len(features) > n_samples:
indices = np.random.choice(len(features), n_samples, replace=False)
features = features[indices]
labels = labels[indices]
# Apply t-SNE
print("Running t-SNE dimensionality reduction...")
reducer = TSNE(n_components=2, random_state=42, verbose=1)
features_2d = reducer.fit_transform(features)
# Create visualization
plt.figure(figsize=(12, 10))
scatter = plt.scatter(features_2d[:, 0], features_2d[:, 1], c=labels, cmap='tab10', alpha=0.6, s=30)
# Add colorbar with class names
cbar = plt.colorbar(scatter, label='Class', ticks=range(len(class_names)))
cbar.ax.set_yticklabels(class_names)
plt.xlabel('t-SNE Component 1')
plt.ylabel('t-SNE Component 2')
plt.title('t-SNE Visualization of DINOv2 Features on CIFAR-10')
plt.tight_layout()
return plt.gcf()
def main() -> None:
print(f"Using device: {DEVICE}")
print(f"Using {MAX_TRAIN_SAMPLES} training samples and {MAX_TEST_SAMPLES} test samples")
# Load DINOv2 model and processor
print("Loading DINOv2 model...")
processor = AutoImageProcessor.from_pretrained("facebook/dinov2-base", use_fast=True)
model = AutoModel.from_pretrained("facebook/dinov2-base")
# Load CIFAR-10 dataset
print("Loading CIFAR-10 dataset...")
dataset = load_dataset("uoft-cs/cifar10")
# Get class names
class_names = dataset["train"].features["label"].names
print(f"CIFAR-10 classes: {class_names}")
# Limit dataset size for faster processing
train_images = dataset["train"]["img"][:MAX_TRAIN_SAMPLES]
train_labels = np.array(dataset["train"]["label"][:MAX_TRAIN_SAMPLES])
test_images = dataset["test"]["img"][:MAX_TEST_SAMPLES]
test_labels = np.array(dataset["test"]["label"][:MAX_TEST_SAMPLES])
# Extract embeddings
print("Extracting training features...")
train_embeddings = extract_embeddings(model, processor, train_images)
print("Extracting test features...")
test_embeddings = extract_embeddings(model, processor, test_images)
# t-SNE visualization
print("\nPerforming t-SNE visualization...")
visualize_features(train_embeddings, train_labels, class_names, n_samples=MAX_TRAIN_SAMPLES)
output_path = 'tsne_visualization_train.png'
plt.savefig(output_path, dpi=150, bbox_inches='tight')
visualize_features(test_embeddings, test_labels, class_names, n_samples=MAX_TEST_SAMPLES)
output_path = 'tsne_visualization_test.png'
plt.savefig(output_path, dpi=150, bbox_inches='tight')
plt.close()
print(f"Saved t-SNE visualization to {output_path}")
if __name__ == "__main__":
main()Question: Why do we use the [CLS] token (index 0) instead of averaging all patch tokens?
💥 Task 2 💥
Using features extracted with DINOv2 foundation model, train a simple sklearn linear classifier (Linear Probing). To do this:
- Initialize linear classifier (e.g.,
LogisticRegression) and fit it to extracted training embeddings and labels. - Evaluate the classifier on both training and test sets.
- Compute accuracy scores for both sets.
Then, compare this approach to training a CNN from scratch. Which one requires more labeled data?
Parameter-Efficient Fine-Tuning (LoRA)
While Linear Probing (Task 2) is fast, it freezes the backbone. To get the best performance, we often want to adapt the model weights. However, DINOv2-Base has 86 Million parameters. Fine-tuning all of them is expensive.
This has led to the development of methods such as LoRA (Low-Rank Adaptation), which enables us to fine-tune the model by adding small, trainable matrices to the attention layers while keeping the main model ‘frozen’.
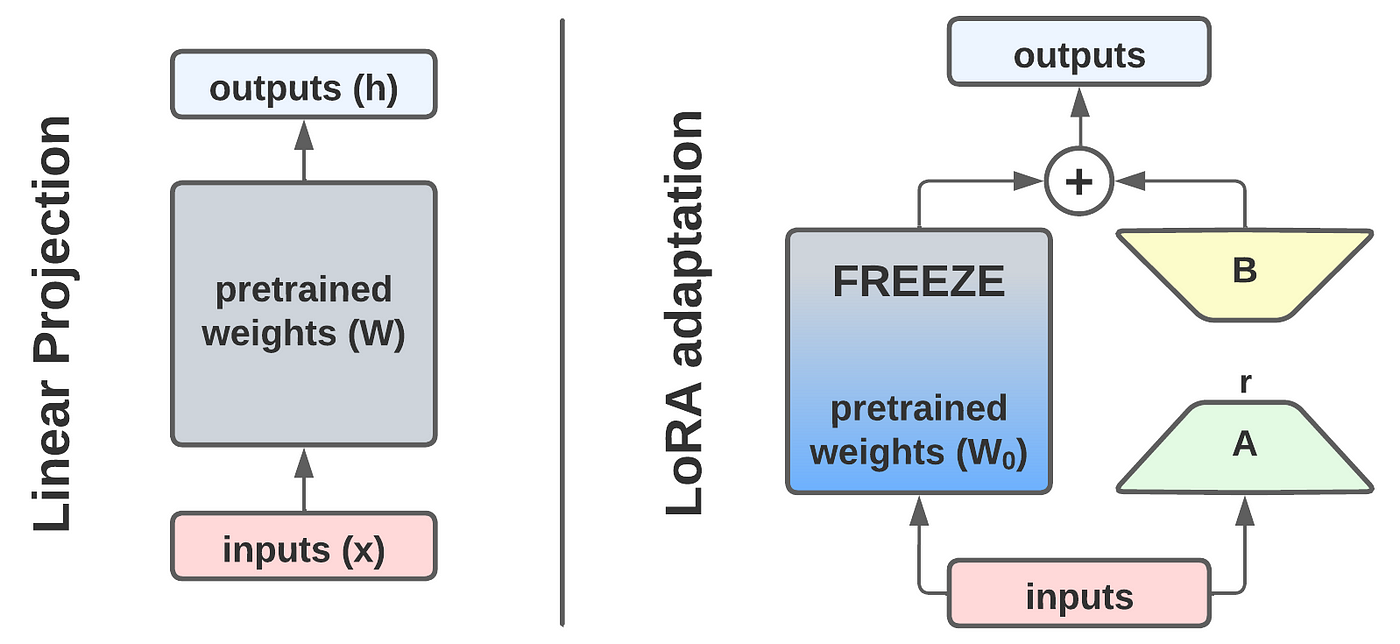
Image source:
LoRA: Low-Rank Adaptation of
Large Language Models
💥 Task 3 💥
Fine-tune a Vision Transformer using LoRA on a subset of CIFAR-10.
- Load a ViT model for image classification (e.g.,
timm/vit_small_patch16_224.augreg_in21k, other model can be found at Hugging Face). - Use peft package to inject LoRA adapters.
- Compare the number of trainable parameters before and after LoRA.
lora.py
from functools import partial
import numpy as np
from datasets import load_dataset
from peft import LoraConfig, get_peft_model
from sklearn.metrics import accuracy_score
from transformers import AutoModelForImageClassification, AutoImageProcessor, TrainingArguments, Trainer
def print_trainable_parameters(model) -> None:
"""Print the number of trainable parameters in the model."""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(f"Trainable params: {trainable_params} | All params: {all_param} | Trainable params [%]: {100 * trainable_params / all_param:.2f}%")
def preprocess(examples: dict, processor: AutoImageProcessor) -> dict:
"""Preprocess images using the provided processor."""
images = [img.convert("RGB") for img in examples["img"]]
inputs = processor(images, return_tensors="pt")
inputs["labels"] = examples["label"]
return inputs
def compute_metrics(eval_pred: tuple[np.ndarray, np.ndarray]) -> dict[str, float]:
"""Compute accuracy metric."""
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return {"accuracy": accuracy_score(labels, predictions)}
def main() -> None:
############# TODO: Student code #####################
# Step 1: Load base model using AutoModelForImageClassification.from_pretrained 10 classes
# and ignore mismatched sizes (`ignore_mismatched_sizes=True`)
model = ...
# Step 2: Load image processor using AutoImageProcessor.from_pretrained
processor = ...
######################################################
############# TODO: Student code #####################
print("--- Before LoRA ---")
# Step 1: Print model trainable parameters before applying LoRA (use print_trainable_parameters function)
# Configure and apply LoRA
config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["qkv"], # timm models use 'qkv'
lora_dropout=0.1,
bias="none",
modules_to_save=["classifier"],
)
lora_model = get_peft_model(model, config)
print("--- After LoRA ---")
# Step 2: Print model trainable parameters after applying LoRA (use print_trainable_parameters function)
######################################################
# Load subset of CIFAR-10 dataset
dataset = load_dataset("uoft-cs/cifar10")
train_dataset = dataset["train"].select(range(5000)) # Use 5000 samples
test_dataset = dataset["test"].select(range(1000)) # Use 1000 samples
train_dataset.set_transform(partial(preprocess, processor=processor))
test_dataset.set_transform(partial(preprocess, processor=processor))
# Training arguments
training_args = TrainingArguments(
output_dir="./vit-lora-cifar10",
num_train_epochs=3,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
learning_rate=5e-4,
eval_strategy="epoch",
save_strategy="epoch",
logging_steps=50,
remove_unused_columns=False,
load_best_model_at_end=True,
)
# Create Trainer
trainer = Trainer(
model=lora_model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
compute_metrics=compute_metrics,
)
############# TODO: Student code #####################
# Step 1: Check accuracy of model with applied LoRA before training using trainer.evaluate()
print("Evaluating before training...")
results = ...
print(f"Test Accuracy before training: {results['eval_accuracy']:.4f}")
# Train
trainer.train()
# Step 2: Check accuracy of model with applied LoRA after training using trainer.evaluate()
print("Evaluating after training...")
lora_results = ...
print(f"Test Accuracy after LoRA: {lora_results['eval_accuracy']:.4f}")
######################################################
if __name__ == "__main__":
main()Knowledge Distillation
The Teacher-Student Paradigm
Foundation models (like the one in Part 1) are accurate but heavy (slow inference, high VRAM). In production (e.g., autonomous drones, mobile apps), we need small models.
Knowledge Distillation (KD) transfers the knowledge from a large Teacher (e.g., ResNet-50) to a small Student (e.g., ResNet-18 or MobileNet). The most common types of KD are:
- Response-Based Distillation - Student mimics Teacher’s output probabilities (logits).
- Feature-Based Distillation - Student mimics Teacher’s intermediate feature maps.
- Relation-Based Distillation - Student mimics relationships between different data points as learned by the Teacher.
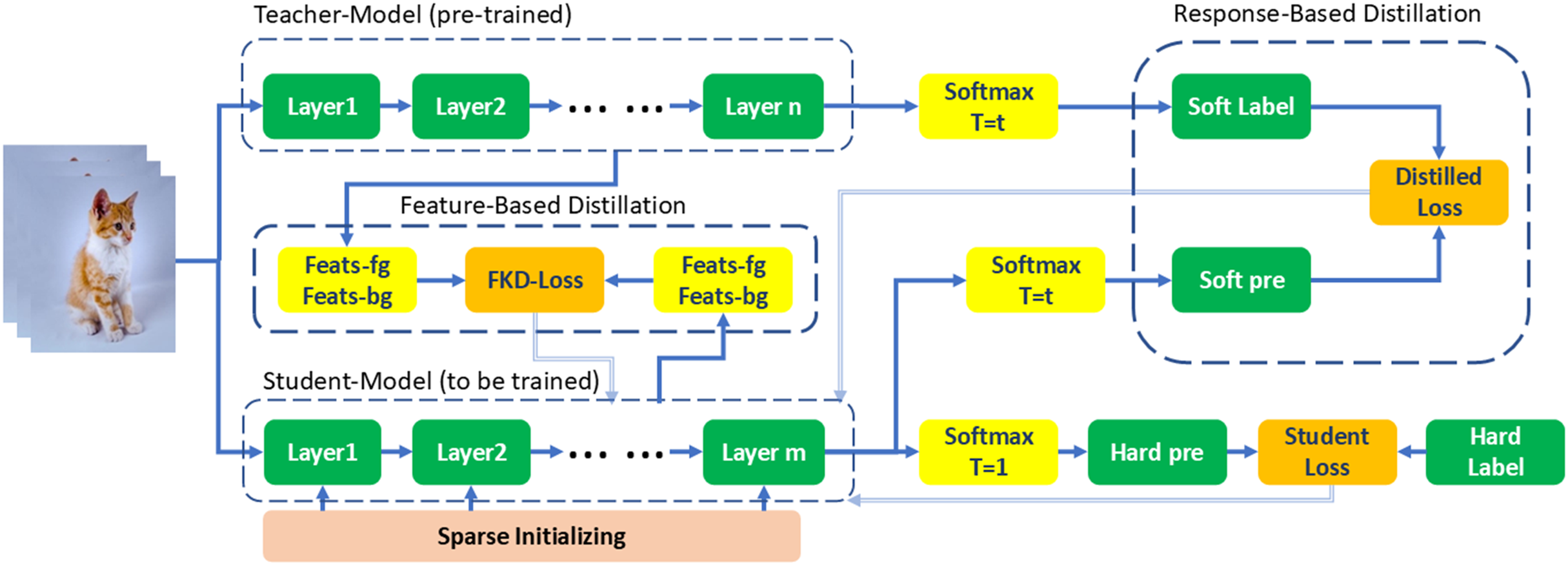
Image source:
Towards optimal sparse
CNNs: sparsity-friendly knowledge distillation through feature
decoupling
The Student minimizes a combined loss:
- Hard Loss: Matches the true label (Ground Truth).
- Soft Loss (Distillation): Matches the Teacher’s probability distribution.
\[ L_{total} = \alpha \cdot L_{CE}(Student, Label) + (1-\alpha) \cdot T^2 \cdot L_{KL}(Student, Teacher) \]
💥 Task 4 💥
Check how “expensive” is model inference. For that purpose
- Initialize Teacher - load a pre-trained ResNet50 from
torchvisionpackage. - Initialize Student - load a ResNet18
(
weights=None) fromtorchvisionpackage. - Benchmark the inference time (latency) of a single image using both models on both the CPU and the GPU. Use a random tensor with the following shape: (1, 3, 224, 224). Average measurements from 100 runs.
💥 Task 5 💥
Write a training loop to train the Student model from scratch (without Teacher) on a subset of CIFAR-10 dataset. Complete the following code gaps to implement standard training. Run model training for 3 epochs and verify the performance of the Student on the test set after training.
train_student_from_scratch.py
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader, Subset
from torchvision.models import resnet18
from torchvision import datasets, transforms
from tqdm import tqdm
# Configuration
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
BATCH_SIZE = 128
NUM_EPOCHS = 3
LEARNING_RATE = 0.001
MAX_TRAIN_SAMPLES = 10000
def prepare_data_loaders():
"""Prepare CIFAR-10 data loaders with appropriate transforms for ResNet.
Returns
-------
train_loader : torch.utils.data.DataLoader
DataLoader for training data
test_loader : torch.utils.data.DataLoader
DataLoader for test data
"""
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_dataset_full = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
train_indices = list(range(min(MAX_TRAIN_SAMPLES, len(train_dataset_full))))
train_dataset = Subset(train_dataset_full, train_indices)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=2, pin_memory=True)
print(f"Train samples: {len(train_dataset)}, Test samples: {len(test_dataset)}")
return train_loader, test_loader
def evaluate_model(model, data_loader):
"""Evaluate model accuracy on a dataset.
Parameters
----------
model : torch.nn.Module
The model to evaluate
data_loader : torch.utils.data.DataLoader
DataLoader containing the evaluation data
Returns
-------
float
Accuracy as a percentage
"""
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in data_loader:
images, labels = images.to(DEVICE), labels.to(DEVICE)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return 100 * correct / total
def initialize_student_model(num_classes=10):
"""Initialize Student model for training from scratch.
Parameters
----------
num_classes : int, optional
Number of output classes (default: 10 for CIFAR-10)
Returns
-------
student : torch.nn.Module
ResNet18 model without pre-trained weights
"""
############# TODO: Student code #####################
# Step 1: Load ResNet18 without pre-trained weights `weights=None`
student = ...
# Step 2: Replace final layer for CIFAR-10 (10 classes) with a new Linear layer with 10 outputs
student.fc = ...
# Step 3: Move model to device
student = ...
######################################################
print(f"Student parameters: {sum(p.numel() for p in student.parameters()):,}")
return student
def train_standard(student, train_loader, test_loader):
"""Train student model from scratch using standard cross-entropy loss.
Parameters
----------
student : torch.nn.Module
Student model to train
train_loader : torch.utils.data.DataLoader
Training data loader
test_loader : torch.utils.data.DataLoader
Test data loader
Returns
-------
float
Final test accuracy
"""
############# TODO: Student code #####################
# Step 1: Initialize optimizer
# - Use torch.optim.Adam with student.parameters() and LEARNING_RATE
optimizer = ...
for epoch in range(1, NUM_EPOCHS + 1):
student.train()
epoch_loss = 0.0
for images, labels in tqdm(train_loader, desc=f"Epoch {epoch}/{NUM_EPOCHS}"):
images, labels = images.to(DEVICE), labels.to(DEVICE)
# Step 2: Student forward pass
outputs = ...
# Step 3: Calculate cross-entropy loss
loss = ...
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
# Step 4: Evaluate after each epoch
train_acc = ...
test_acc = ...
avg_loss = epoch_loss / len(train_loader)
print(f"Epoch {epoch}: Loss={avg_loss:.4f}, Train Acc={train_acc:.2f}%, Test Acc={test_acc:.2f}%")
######################################################
return test_acc
def main():
"""Train Student from Scratch."""
print(f"Device: {DEVICE} | Epochs: {NUM_EPOCHS} | Batch: {BATCH_SIZE} | LR: {LEARNING_RATE}\n")
# Prepare data
train_loader, test_loader = prepare_data_loaders()
# Initialize student
student = initialize_student_model(num_classes=10)
# Train student from scratch
print("\nTraining Student from Scratch...")
test_acc = train_standard(student, train_loader, test_loader)
print(f"Final Test Accuracy: {test_acc:.2f}%")
if __name__ == "__main__":
main()💥 Task 6 💥
Using the below source code, implement Knowledge Distillation to train the Student model with the Teacher’s guidance. You must complete the gaps in the functions to perform a distillation training step that forwards the same image through both the Teacher (frozen) and the Student (trainable). Key details:
- Teacher is in eval() mode.
- Student is in train() mode.
- Temperature (T): Start with T=4. Higher T makes the probability distribution “softer” (flatter), revealing more information about the relationships between classes (e.g., “this image is 90% car, 9% truck, 1% dog”).
Train the student for 3 epochs on the CIFAR-10 subset. Verify the performance of the Student on the test set after training. Then answer the following questions:
- How does the accuracy of the distilled Student compare to a Student trained from scratch (without Teacher)? Did the distilled student achieve higher accuracy than the student trained from scratch?
- Analyze the confusion matrix of the distilled Student. Does it make “smarter” mistakes compared to the Student trained from scratch?
[Optional task] Experiment with different Student architectures (e.g., MobileNetV2, EfficientNet) and observe how distillation affects their performance.
knowledge_distillation.py
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader, Subset
from torchvision.models import resnet50, ResNet50_Weights, resnet18
from torchvision import datasets, transforms
from tqdm import tqdm
# Configuration
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
BATCH_SIZE = 128
NUM_EPOCHS = 3
LEARNING_RATE = 0.001
MAX_TRAIN_SAMPLES = 10000
TEMPERATURE = 4.0
ALPHA = 0.5
def prepare_data_loaders():
"""Prepare CIFAR-10 data loaders with appropriate transforms for ResNet.
Returns
-------
train_loader : torch.utils.data.DataLoader
DataLoader for training data
test_loader : torch.utils.data.DataLoader
DataLoader for test data
"""
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_dataset_full = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
train_indices = list(range(min(MAX_TRAIN_SAMPLES, len(train_dataset_full))))
train_dataset = Subset(train_dataset_full, train_indices)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=2, pin_memory=True)
print(f"Train samples: {len(train_dataset)}, Test samples: {len(test_dataset)}")
return train_loader, test_loader
def evaluate_model(model, data_loader):
"""Evaluate model accuracy on a dataset.
Parameters
----------
model : torch.nn.Module
The model to evaluate
data_loader : torch.utils.data.DataLoader
DataLoader containing the evaluation data
Returns
-------
float
Accuracy as a percentage
"""
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in data_loader:
images, labels = images.to(DEVICE), labels.to(DEVICE)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return 100 * correct / total
def initialize_teacher_student(num_classes=10):
"""Initialize Teacher and Student models for knowledge distillation.
Parameters
----------
num_classes : int, optional
Number of output classes (default: 10 for CIFAR-10)
Returns
-------
teacher : torch.nn.Module
Pre-trained ResNet50 model (frozen)
student : torch.nn.Module
ResNet18 model without pre-trained weights (trainable)
"""
############# TODO: Student code #####################
# Step 1: Initialize Teacher (ResNet50) with pre-trained weights (`weights=ResNet50_Weights.IMAGENET1K_V2`)
teacher = ...
teacher.fc = ...
# Step 2: Move Teacher to device and set to eval mode
teacher = ...
# Freeze Teacher parameters
for param in teacher.parameters():
param.requires_grad = False
# Step 3: Initialize Student (ResNet18) without pre-trained weights (`weights=None`)
student = ...
# Step 4: Replace final layer for CIFAR-10 (10 classes) with a new Linear layer with 10 outputs
student.fc = ...
# Step 5: Move Student to device
student = ...
######################################################
print(f"Teacher parameters: {sum(p.numel() for p in teacher.parameters()):,}")
print(f"Student parameters: {sum(p.numel() for p in student.parameters()):,}")
return teacher, student
def train_batch_distillation(teacher, student, images, labels, optimizer, T=4.0, alpha=0.5):
"""Train student model using knowledge distillation from teacher model.
Parameters
----------
teacher : torch.nn.Module
Teacher model (frozen, pre-trained)
student : torch.nn.Module
Student model (trainable)
images : torch.Tensor
Input batch of images
labels : torch.Tensor
Ground truth labels
optimizer : torch.optim.Optimizer
Optimizer for student model
T : float, optional
Temperature for softening probability distributions (default: 4.0)
alpha : float, optional
Weight for hard loss vs soft loss (default: 0.5)
Returns
-------
float
Combined loss value
"""
############# TODO: Student code #####################
# Step 1: Get teacher predictions (no gradients)
# - Set teacher to eval() mode
# - Use torch.no_grad() context
# - Forward teacher model and assign the output to `teacher_logits`
teacher.eval()
with torch.no_grad():
teacher_logits = teacher(images)
# Step 2: Get student predictions
# - Set student to train() mode
# - Forward student model and assign the output to `student_logits`
# Step 3: Calculate Hard Loss (cross-entropy with student_logits and true labels)
loss_ce = ...
# Calculate Soft Loss (KL divergence with teacher's soft targets)
# - Apply temperature T to both teacher and student logits
# - Teacher: F.softmax(teacher_logits / T, dim=1)
# - Student: F.log_softmax(student_logits / T, dim=1)
# - Multiply result by T^2 to maintain gradient scale
soft_targets = F.softmax(teacher_logits / T, dim=1)
soft_prob = F.log_softmax(student_logits / T, dim=1)
loss_kl = F.kl_div(soft_prob, soft_targets, reduction='batchmean') * (T ** 2)
# Step 4: Combine losses
# - loss = alpha * CE loss + (1 - alpha) * KL loss
loss = ...
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
######################################################
return loss.item()
def train_with_distillation(teacher, student, train_loader, test_loader):
"""
Train student model with knowledge distillation from teacher.
Parameters
----------
teacher : torch.nn.Module
Teacher model (frozen)
student : torch.nn.Module
Student model to train
train_loader : torch.utils.data.DataLoader
Training data loader
test_loader : torch.utils.data.DataLoader
Test data loader
Returns
-------
float
Final test accuracy
"""
############# TODO: Student code #####################
# Step 1: Initialize optimizer
# - Use torch.optim.Adam with student.parameters() and LEARNING_RATE
optimizer = ...
for epoch in range(1, NUM_EPOCHS + 1):
epoch_loss = 0.0
for images, labels in tqdm(train_loader, desc=f"Epoch {epoch}/{NUM_EPOCHS}"):
images, labels = images.to(DEVICE), labels.to(DEVICE)
# Step 2: Train with distillation by calling train_batch_distillation with TEMPERATURE and ALPHA
loss = ...
epoch_loss += loss
# Step 3: Evaluate
train_acc = ...
test_acc = ...
avg_loss = epoch_loss / len(train_loader)
print(f"Epoch {epoch}: Loss={avg_loss:.4f}, Train Acc={train_acc:.2f}%, Test Acc={test_acc:.2f}%")
######################################################
return test_acc
def main():
"""Train Student with Knowledge Distillation."""
print(f"Device: {DEVICE} | Epochs: {NUM_EPOCHS} | Batch: {BATCH_SIZE} | LR: {LEARNING_RATE}")
print(f"Temperature: {TEMPERATURE} | Alpha: {ALPHA}\n")
# Prepare data
train_loader, test_loader = prepare_data_loaders()
# Initialize teacher and student
teacher, student = initialize_teacher_student(num_classes=10)
# Train student with distillation
print("\nTraining Student with Knowledge Distillation...")
test_acc = train_with_distillation(teacher, student, train_loader, test_loader)
# Compare with teacher
teacher_acc = evaluate_model(teacher, test_loader)
print(f"Teacher Test Accuracy: {teacher_acc:.2f}%")
print(f"Student Test Accuracy: {test_acc:.2f}%")
print(f"Accuracy Gap: {teacher_acc - test_acc:.2f}%")
if __name__ == "__main__":
main()💥 Task 7 💥
Feature-Based Distillation. Standard distillation uses the final output (logits). However, we can also force the Student to mimic the intermediate feature maps of the Teacher.
- Challenge: Teacher features might have 2048 channels, while Student features have 512 channels.
- Solution: Use a 1×1 Convolution layer to project the Student’s features up to the Teacher’s dimension before calculating the Mean Squared Error (MSE) loss.
\[ L_{feat} = || F_{teacher} - \text{Conv}(F_{student}) ||^2_2 \]
Implement a simplified version of this by extracting the features before the final fully connected layer.